Det finns några saker som utmärker välskriven HTML-kod. God HTML-kod är inte skriven så att den bara fungerar i några få webbläsare, eller i värsta fall bara i en enda. Den är inte skriven så att man med HTML-koden bryter mot givna regler eller för att skapa visuella effekter. Uppdaterad 2010-07-31)
Proprietär kod kontra standarder
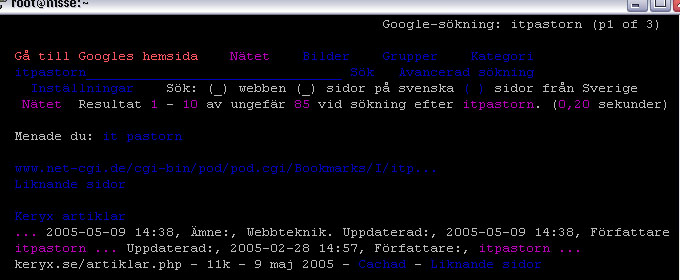
I webbens barndom var webbläsarna inte ens grafiska. Har du aldrig sett ett text-baserat gränssnitt, så starta kommandotolken om du kör Windows och skriv exempelvis dir. Detta är ett textbaserat gränssnitt och det finns än idag webbläsare som jobbar i textläge. Vanligast bland dem är Lynx, som visas på bilden. Det du ser är resultatet av en sökning på Google efter mitt alias, itpastorn
.
När den första webbläsaren som kunde visa bilder, Mosaic, fick den förmågan, så gjordes det på på ett sätt som kom att bilda skola för de närmaste årens utveckling. Gänget bakom Mosaic införde helt enkelt ett element <img> som man inte först blivit helt överens med andra webbläsares tillverkare om. De närmaste åren skulle främst Netscape driva på utvecklingen och självsvåldigt skapa massor av nya HTML-element. På nätet kryllade det av sidor med logotypen Best viewed with Netscape
. Element och attribut som införts av en enskild tillverkare, men som inte blivit erkända av standardiseringsorganet World Wide Web Consortium kallas proprietära.
Om man använder proprietär kod så går man dels miste om det helhetstänkande som de skarpaste hjärnorna på webben kommit fram till, dels riskerar man skapa en kod som inte fungerar på andra plattformar än den man testat på. Även om Microsoft har haft en starkt dominerande ställning de senaste åren, så har historien tydligt visat att det är mycket dumt att koda bara för ett fabrikat. God kod följer fastslagna standarder från bland annat W3C. God kod har inga element och inga attribut som är proprietära.
God kod är Well Formed
När man skriver sina taggar så bör de nästlas på rätt sätt. Man skall avsluta dem i motsatt ordning som de öppnades. Så här: <em><span>foobar</span></em>. Lägg märke till att taggen span avslutas först, eftersom den påbörjades sist. Detta är alltså dålig kod: <em><span>foobar</em></span>. Skulle du testa denna kod i en webbläsare, så förlåter den dig misstaget, men det är ändå dumt. Argumenten mot ej välformad kod har formulerats så här:
- Felaktigt nästlad kod är svårare att hitta fel i och svårare att underhålla.
- Information från felaktigt nästlad kod är svårare att återanvända i andra sammanhang.
- Förekomsten av felaktigt nästlad kod tvingar dem som gör webbläsare att skriva mer omständiga koder som tolkar sidorna. Det gör webbläsarna långsammare, större och mer minneskrävande. Att webbläsare har förlåtit generationer av slarviga HTML-kodare och dålig kod skapad av program som Frontpage är inte bra.
- XHTML kräver att koden är well-formed. I en webbläsare som har äkta stöd för XHTML, vilket Firefox, Chrome, Opera och Safari har till skillnad från Internet Explorer (fram till och med version 8), så kommer en sida som inte är well-formed att visas över huvud taget, om sidan skickats med en XHTML MIME-deklaration..
I och med arbetet runt HTML5, så har vissa av dessa argument granskats på nytt och delvis reviderats. Regeln om att koden bör vara välformad står sig, men mer och mer så framstår argumenten om begriplighet och underhåll som starkast. HTML-koden skapar efter att den tolkats en objektstruktur i webbläsaren, DOM. När HTML-koden inte är välformad, så är det synnerligen svårt att bedöma hur denna DOM är uppbyggd. Då blir det svårt att förutse hur CSS kod och JavaScript kommer fungera, eftersom de utgår från sidans DOM, inte från dess råa HTML-kod.
God kod är valid
Utöver kravet på taggarnas nästling, så finns det vissa andra regler om deras inbördes ordning. Om man vill ha ett citat som rubrik bör man skriva så här: . <h1><q>foobar</q></h2>. Taggen för citat skall alltså stå inuti rubriktaggen. Det här är fel: <q><h1>foobar</h1></q>. Det är visserligen well-formed, men det är trots det inte valid. Kod kan vara det första utan att vara det andra, men den kan inte vara valid, utan att samtidigt vara well-formed.
Exakt vilka regler är det då som gäller? Var finns de uppskrivna? Fram till, men inte med HTML version 5, så är svaret att det vet man genom att titta på dokumentets doctype. I den hänvisas till det som kallas en Document Type Definition, som förkortas DTD. En DTD är inte lätt att läsa eftersom det är ett dokument som skrivits för att kunna tolkas av datorer, snarare än människor. När man vill kontrollera om man har ett dokument som är korrekt, så validerar man det. Under utvecklingen av en sida, så bör man validera sin kod gång efter annan. Den mest kända validatorn finns på adressen validator.w3.org. Vad validatorn gör är att den jämför ditt dokument med DTD:n och ser efter som det följer de däri angivna reglerna.
HTML5 har regler kring validitet som gör validering med DTD-tekniken omöjlig. En DTD kan inte beskriva villkor och HTML5 har exempelvis detta villkor:
<div> <!-- Blocktagg börjar -->
<p> <!-- Blockelement inuti blockelement = OK --></p>
<span> <!-- Inline-element som syskon till blockelement. Inte OK --></span>
</div>
Denna kod är helt OK enligt reglerna för HTML 4 och XHTML 1.x, men den är förbjuden enligt HTML5. Inuti ett block-element som div får man numera – på barn-nivå – ha antingen inline eller block element, men inte både och. Och detta kan man inte kontrollera med DTD-tekniken. Av bland annat detta skäl, så använder HTML5 validatorn en mer komplicerad algoritm. (Mer om olika versioner av HTML i nästa artikel.)
God kod är semantisk
Nu är det så med regler, att man många gånger kan bryta mot deras syfte även om man följer deras bokstav. Låt säga att du som läser detta dokument undrat hur jag gör mina tooltips på ord och förkortningar. Man studerar denna sidas källkod och hittar följande kod: <dfn title="Tooltips är kommentarer som syns när man svävar med markören över ett objekt">tooltips</dfn>. Elementet är alltså <dfn> med attributet title. Glad i hågen sätter nybörjaren igång och skriver följande felaktiga kod: Anmäl dig<dfn title="As Soon As Possible">ASAP</dfn>. Sedan kollar man i sin webbläsare och voila, det fungerar! Men det är fel, för elementet <dfn> betyder definition
och skall användas för ord man vi just definiera. ASAP är inte ett ord, utan en förkortning. Till förkortningar skall man använda elementet <abbr>. (Från och med HTML5 så utgår alternativet <acronym>. Vilket av dessa två element mans skulle använda ledde bara till oändliga diskussioner utan att skillnaden någonsin skapade en egentlig nytta).
Standarderna för HTML och XHTML kan alltså definieras på två sätt: Dels genom en DTD, som vi talade om ovan, och dels genom
rekommendationer. Dessa dokument motsvarar
vad som i andra sammanhang kallas just standarder
. De är skrivna för att tolkas av människor, inte maskiner, och i dem anges hur olika element skall brukas.
God kod följer alltså en språklig logik. Sådan språkligt logisk kod kallas – och nu passar elementet <dfn> – semantisk. Alla HTML-taggar skall alltså användas för att uttrycka vilken funktion det som de inringar fyller i sammanhanget. Om vi backar lite och tar de enkla taggarna vi bekantade oss med i förra artikeln i denna serie så ser vi detta tydligt.
<h1>- Detta är
heading one
, alltså huvudrubriken. <h2>- Detta är
heading two
, alltså rubriker på nivån därinunder. <p>- Detta är
paragraph
, alltså stycken.
Semantisk kod missbrukar inte element
Nu är det så att webbläsare har en förinställd visning av alla element. <h1> skapar normalt mycket stor, fetstilt text. Av det skälet väljer många (och jag har själv gjort det i min forna okunnighet) att inte använda heading one
, utan har heading three
eller något liknande som huvudrubrik. Detta är att blanda ihop funktion med presentation, innehåll med design.
Ett annat vanligt missbruk av taggar har varit att avsluta text med <p>. Standardinställningen är nämligen att ett stycke har en rads avstånd ovanför sig. Detta missbrukas då som dubbla radslutstecken för att skapa avstånd till det som kommer efter.
Det vanligaste missbruket genom tiderna är att använda tabeller för att skapa sidstruktur. Om man vill ha en layout med sidhuvud och spalter, vilket är det vanligaste på hemsidor, så fanns det länge inga andra alternativ än att göra detta med tabeller, vars celler inte hade några kantlinjer. Länge var det alltså det enda alternativet och detta missbruk kan därför anses vara förlåtligt – på den tiden webbläsarna inte stödde CSS som de gör idag!
Semantisk kod struntar i utseendet
Många element och attribut skapades en gång i tiden för att ha en specifik funktion att styra utseendet på en sida. Du behöver känna till taggar som <font>, <center> <b> och <i>, men du skall inte använda dem! Du styr idag typsnitt med CSS i stället för med font-taggar. Du centrerar med CSS, inte med center-taggen. På samma sätt skapar du fetstilt text och kursiv text med CSS – såvida du inte vill ha dessa effekter av ett språkligt skäl. Kanske skall ett ord betonas. Då använder du taggen <em> som betyder emfas
, betoning. Vill man betona något ännu starkare så används taggen <strong>. Frågan är alltså varför jag vill ha kursiv eller fet text. Är det för att ord skall betonas, så gör jag det med taggar, är det bara för den visuella effektens skull så gör jag det med CSS.
För att vara bakåtkompatibla med äldre tiders skräpkod, så finns det webbstandarder som tillåter somliga element och somliga attribut vars syfte endast är att kontrollera designen. Men de är nedvärderade (engelska: deprecated
). En nedvärderad tagg finns för att man skall kunna enklare göra övergången från gammal kod till modern. Men att idag använda dem i nya projekt är ren och skär idioti.
Nu vet vi tillräckligt mycket för att kunna välja vilken version av (X)HTML man bör välja för sin hemsida. Det är ämnet för nästa artikel i denna serie.